
Transparent live-first benchmark harness for evaluating model capability inside the OpenClaw runtime.
102 active scenarios, 162 catalog scenarios, deterministic grading, and OpenClaw-native coverage.
OpenClawProBench focuses on real OpenClaw execution with deterministic grading, structured reports, and benchmark-profile selection. The default ranking path is the core profile; broader active coverage remains available through intelligence, coverage, native, and full.
The current worktree inventory reports 102 active scenarios and 162 total catalog scenarios (60 incubating) via python3 run.py inventory --json and python3 run.py inventory --benchmark-status all --json.
Browse the public leaderboard and benchmark cases at suyoumo.github.io/bench.
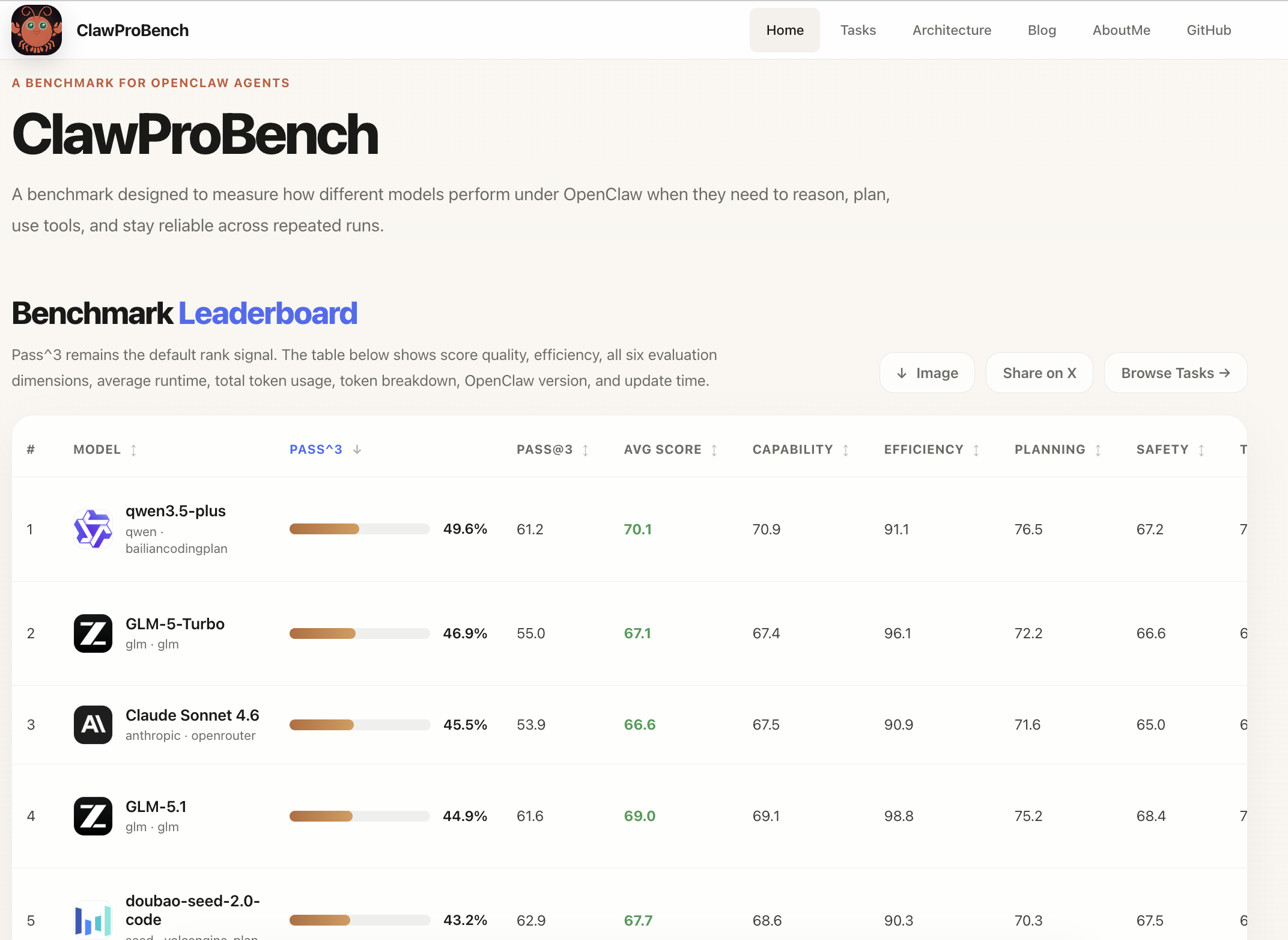
v1.0.2- Addedkimi-for-coding,gemma4-31b, andkimi-k2-thinking; improved image download flows for easier mobile-device browsing.v1.0.1- Addedqwen3-coder-next,doubao-seed-code,qwen3-max-2026-01-23, andqwen3.6plusrerun withbailiancodingplan; added model image download and benchmark sharing to Twitter; fixed completed-report resume overwrite,tool_use_14graceful fallback on skills inventory load failure,tool_use_17invalid JSON and missing-file tolerance, andaudit_scenario_quality.pycompatibility.v1.0.0- OpenClawProBench released with 102 tasks across 6 domains, with 3-try runs, checkpoint resume, and cross-environment resume support.
- Default ranking path:
core - Extended active capability suite:
intelligence - Native-only slice:
native - Multi-trial runs are supported via
--trials N - Reports expose
avg_score,max_score, coverage-aware summaries, cost, latency, and resume metadata - Interrupted runs can continue with
--continueor--resume-from, and execution failures can be re-queued with--rerun-execution-failures
We recommend using uv for fast, reliable Python environment setup:
pip install uv
uv venv --python 3.11
source .venv/bin/activate
uv pip install -r requirements.txtBefore running the benchmark, make sure your local OpenClaw runtime is available:
openclaw --help
openclaw agents list --jsonInspect the benchmark catalog and validate the scenario set:
python3 run.py inventory
python3 run.py inventory --json
python3 run.py dryRun a one-trial smoke on the default ranking benchmark:
python3 run.py run \
--model '<MODEL>' \
--execution-mode live \
--benchmark-profile core \
--trials 1 \
--cleanup-agentsRun the full default benchmark:
python3 run.py run \
--model '<MODEL>' \
--execution-mode live \
--benchmark-profile core \
--trials 3 \
--cleanup-agentsCompare generated reports:
python3 run.py compare --results-dir resultsFor isolated same-host runs, the harness also supports:
--openclaw-profile--openclaw-state-dir--openclaw-config-path--openclaw-gateway-port--openclaw-binary
| Profile | Active scenarios | Purpose |
|---|---|---|
core |
26 | Default ranking suite |
intelligence |
95 | Extended active capability benchmark |
coverage |
7 | Lower-stakes breadth and regression slice |
native |
36 | Active OpenClaw-native slice only |
full |
102 | Union of all active scenarios |
The benchmark catalog also includes 60 incubating scenarios that can be inspected with --benchmark-status all.
Live runs expect a working local openclaw CLI plus the auth and config required by the surfaces exercised by the selected scenarios. If your binary is not on PATH, set OPENCLAW_BINARY or pass --openclaw-binary.
config/openclaw.json.template is provided as a reference template for local OpenClaw configuration and isolated-run setups.
run.py: CLI entrypoint forinventory,dry,run, andcompareharness/: loader, runner, scoring, reporting, and live OpenClaw bridgescenarios/: benchmark tasks in YAMLdatasets/: seeded live-task data and optional setup / teardown scriptscustom_checks/: scenario-specific grading logictests/: regression coverage for loader, runner, scoring, and reportingdocs/: public assets plus evaluation validation and benchmark-profile policy
Benchmark reports are written to results/. They are generated runtime artifacts and are intentionally ignored by version control in this repo layout.
If you use OpenClawProBench in your research, please cite:
@misc{openclawprobench2026,
title={OpenClawProBench — a transparent benchmark for true intelligence in real-world AI agents.},
author={suyoumo},
year={2026},
url={https://github.com/suyoumo/OpenClawProBench}
}We welcome issues, documentation fixes, scenario improvements, grader hardening, and benchmark-engine contributions. See CONTRIBUTING.md for setup and validation guidance.
This project was informed by prior open-source work on agent evaluation, benchmark design, and real-world task assessment.
We drew ideas from projects such as PinchBench, Claw-Eval, AgencyBench, and related agent-benchmark efforts, especially in areas like task design, evaluation methodology, harness structure, and public benchmark presentation.
Some tasks in this repository are adapted and reworked from earlier public benchmark-style task sets into the OpenClaw runtime and grading framework.
Public contributor list: waiting.

Join our WeChat discussion group to discuss OpenClaw with other users and builders.