
tokenizers
No description
Description
<p align="center"> <br> <img src="https://huggingface.co/landing/assets/tokenizers/tokenizers-logo.png" width="600"/> <br> <p> <p align="center"> <a href="https://badge.fury.io/py/tokenizers"> <img alt="Build" src="https://badge.fury.io/py/tokenizers.svg"> </a> <a href="https://github.com/huggingface/tokenizers/blob/master/LICENSE"> <img alt="GitHub" src="https://img.shields.io/github/license/huggingface/tokenizers.svg?color=blue"> </a> </p> <br> # Tokenizers Provides an implementation of today's most used tokenizers, with a focus on performance and versatility. Bindings over the [Rust](https://github.com/huggingface/tokenizers/tree/master/tokenizers) implementation. If you are interested in the High-level design, you can go check it there. Otherwise, let's dive in! ## Main features: - Train new vocabularies and tokenize using 4 pre-made tokenizers (Bert WordPiece and the 3 most common BPE versions). - Extremely fast (both training and tokenization), thanks to the Rust implementation. Takes less than 20 seconds to tokenize a GB of text on a server's CPU. - Easy to use, but also extremely versatile. - Designed for research and production. - Normalization comes with alignments tracking. It's always possible to get the part of the original sentence that corresponds to a given token. - Does all the pre-processing: Truncate, Pad, add the special tokens your model needs. ### Installation #### With pip: ```bash pip install tokenizers ``` #### From sources: To use this method, you need to have the Rust installed: ```bash # Install with: curl https://sh.rustup.rs -sSf | sh -s -- -y export PATH="$HOME/.cargo/bin:$PATH" ``` Once Rust is installed, you can compile doing the following ```bash git clone https://github.com/huggingface/tokenizers cd tokenizers/bindings/python # Create a virtual env (you can use yours as well) python -m venv .env source .env/bin/activate # Install `tokenizers` in the current virtual env pip install -e . ``` ### Load a pretrained tokenizer from the Hub ```python from tokenizers import Tokenizer tokenizer = Tokenizer.from_pretrained("bert-base-cased") ``` ### Using the provided Tokenizers We provide some pre-build tokenizers to cover the most common cases. You can easily load one of these using some `vocab.json` and `merges.txt` files: ```python from tokenizers import CharBPETokenizer # Initialize a tokenizer vocab = "./path/to/vocab.json" merges = "./path/to/merges.txt" tokenizer = CharBPETokenizer(vocab, merges) # And then encode: encoded = tokenizer.encode("I can feel the magic, can you?") print(encoded.ids) print(encoded.tokens) ``` And you can train them just as simply: ```python from tokenizers import CharBPETokenizer # Initialize a tokenizer tokenizer = CharBPETokenizer() # Then train it! tokenizer.train([ "./path/to/files/1.txt", "./path/to/files/2.txt" ]) # Now, let's use it: encoded = tokenizer.encode("I can feel the magic, can you?") # And finally save it somewhere tokenizer.save("./path/to/directory/my-bpe.tokenizer.json") ``` #### Provided Tokenizers - `CharBPETokenizer`: The original BPE - `ByteLevelBPETokenizer`: The byte level version of the BPE - `SentencePieceBPETokenizer`: A BPE implementation compatible with the one used by SentencePiece - `BertWordPieceTokenizer`: The famous Bert tokenizer, using WordPiece All of these can be used and trained as explained above! ### Build your own Whenever these provided tokenizers don't give you enough freedom, you can build your own tokenizer, by putting all the different parts you need together. You can check how we implemented the [provided tokenizers](https://github.com/huggingface/tokenizers/tree/master/bindings/python/py_src/tokenizers/implementations) and adapt them easily to your own needs. #### Building a byte-level BPE Here is an example showing how to build your own byte-level BPE by putting all the different pieces together, and then saving it to a single file: ```python from tokenizers import Tokenizer, models, pre_tokenizers, decoders, trainers, processors # Initialize a tokenizer tokenizer = Tokenizer(models.BPE()) # Customize pre-tokenization and decoding tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=True) tokenizer.decoder = decoders.ByteLevel() tokenizer.post_processor = processors.ByteLevel(trim_offsets=True) # And then train trainer = trainers.BpeTrainer( vocab_size=20000, min_frequency=2, initial_alphabet=pre_tokenizers.ByteLevel.alphabet() ) tokenizer.train([ "./path/to/dataset/1.txt", "./path/to/dataset/2.txt", "./path/to/dataset/3.txt" ], trainer=trainer) # And Save it tokenizer.save("byte-level-bpe.tokenizer.json", pretty=True) ``` Now, when you want to use this tokenizer, this is as simple as: ```python from tokenizers import Tokenizer tokenizer = Tokenizer.from_file("byte-level-bpe.tokenizer.json") encoded = tokenizer.encode("I can feel the magic, can you?")
Release History
| Version | Changes | Urgency | Date |
|---|---|---|---|
| v0.23.1 | ## TL;DR `tokenizers 0.23.1` is the first proper stable release in the `0.23` line — `0.23.0` only ever shipped as `rc0` because the release pipeline itself was broken (Node side hadn't shipped multi-platform binaries since 2023, Python side was on `pyo3 0.27` without free-threaded support). `0.23.1` is the version where everything actually goes out the door together: full Node multi-platform wheels for the first time in years, Python 3.14 (regular **and** free-threaded `3.14t`), full type hi | High | 4/27/2026 |
| 0.22.2 | Imported from PyPI (0.22.2) | Low | 4/21/2026 |
| v0.22.2 | ## What's Changed Okay mostly doing the release for these PR: * Update deserialize of added tokens by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1891 * update stub for typing by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1896 * bump PyO3 to 0.26 by @davidhewitt in https://github.com/huggingface/tokenizers/pull/1901 <img width="2400" height="1200" alt="image" src="https://github.com/user-attachments/assets/0b974453-1fc6-4393-84ea-da99269e2b34" / | Low | 12/2/2025 |
| v0.22.2 | ## What's Changed Okay mostly doing the release for these PR: * Update deserialize of added tokens by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1891 * update stub for typing by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1896 * bump PyO3 to 0.26 by @davidhewitt in https://github.com/huggingface/tokenizers/pull/1901 <img width="2400" height="1200" alt="image" src="https://github.com/user-attachments/assets/0b974453-1fc6-4393-84ea-da99269e2b34" / | Low | 12/2/2025 |
| v0.22.2 | ## What's Changed Okay mostly doing the release for these PR: * Update deserialize of added tokens by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1891 * update stub for typing by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1896 * bump PyO3 to 0.26 by @davidhewitt in https://github.com/huggingface/tokenizers/pull/1901 <img width="2400" height="1200" alt="image" src="https://github.com/user-attachments/assets/0b974453-1fc6-4393-84ea-da99269e2b34" / | Low | 12/2/2025 |
| v0.22.2 | ## What's Changed Okay mostly doing the release for these PR: * Update deserialize of added tokens by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1891 * update stub for typing by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1896 * bump PyO3 to 0.26 by @davidhewitt in https://github.com/huggingface/tokenizers/pull/1901 <img width="2400" height="1200" alt="image" src="https://github.com/user-attachments/assets/0b974453-1fc6-4393-84ea-da99269e2b34" / | Low | 12/2/2025 |
| v0.22.2 | ## What's Changed Okay mostly doing the release for these PR: * Update deserialize of added tokens by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1891 * update stub for typing by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1896 * bump PyO3 to 0.26 by @davidhewitt in https://github.com/huggingface/tokenizers/pull/1901 <img width="2400" height="1200" alt="image" src="https://github.com/user-attachments/assets/0b974453-1fc6-4393-84ea-da99269e2b34" / | Low | 12/2/2025 |
| v0.22.2 | ## What's Changed Okay mostly doing the release for these PR: * Update deserialize of added tokens by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1891 * update stub for typing by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1896 * bump PyO3 to 0.26 by @davidhewitt in https://github.com/huggingface/tokenizers/pull/1901 <img width="2400" height="1200" alt="image" src="https://github.com/user-attachments/assets/0b974453-1fc6-4393-84ea-da99269e2b34" / | Low | 12/2/2025 |
| v0.22.1 | # Release v0.22.1 Main change: - Bump huggingface_hub upper version (#1866) from @Wauplin - chore(trainer): add and improve trainer signature (#1838) from @shenxiangzhuang - Some doc updates: c91d76ae558ca2dc1aa725959e65dc21bf1fed7e, 7b0217894c1e2baed7354ab41503841b47af7cf9, 57eb8d7d9564621221784f7949b9efdeb7a49ac1 | Low | 9/19/2025 |
| v0.22.0 | ## What's Changed * Bump on-headers and compression in /tokenizers/examples/unstable_wasm/www by @dependabot[bot] in https://github.com/huggingface/tokenizers/pull/1827 * Implement `from_bytes` and `read_bytes` Methods in WordPiece Tokenizer for WebAssembly Compatibility by @sondalex in https://github.com/huggingface/tokenizers/pull/1758 * fix: use AHashMap to fix compile error by @b00f in https://github.com/huggingface/tokenizers/pull/1840 * New stream by @ArthurZucker in https://github.com | Low | 8/29/2025 |
| v0.21.4 | **Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.21.3...v0.21.4 No change, the 0.21.3 release failed, this is just a re-release. https://github.com/huggingface/tokenizers/releases/tag/v0.21.3 | Low | 7/28/2025 |
| v0.21.3 | ## What's Changed * Clippy fixes. by @Narsil in https://github.com/huggingface/tokenizers/pull/1818 * Fixed an introduced backward breaking change in our Rust APIs. **Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.21.2...v0.21.3 | Low | 7/4/2025 |
| v0.21.2 | ## What's Changed This release if focused around some performance optimization, enabling broader python no gil support, and fixing some onig issues! * Update the release builds following 0.21.1. by @Narsil in https://github.com/huggingface/tokenizers/pull/1746 * replace lazy_static with stabilized std::sync::LazyLock in 1.80 by @sftse in https://github.com/huggingface/tokenizers/pull/1739 * Fix no-onig no-wasm builds by @414owen in https://github.com/huggingface/tokenizers/pull/1772 | Low | 6/24/2025 |
| v0.21.1 | ## What's Changed * Update dev version and pyproject.toml by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1693 * Add feature flag hint to README.md, fixes #1633 by @sftse in https://github.com/huggingface/tokenizers/pull/1709 * Upgrade to PyO3 0.23 by @Narsil in https://github.com/huggingface/tokenizers/pull/1708 * Fixing the README. by @Narsil in https://github.com/huggingface/tokenizers/pull/1714 * Fix typo in Split docstrings by @Dylan-Harden3 in https://github.com/hug | Low | 3/13/2025 |
| v0.21.1rc0 | ## What's Changed * Update dev version and pyproject.toml by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1693 * Add feature flag hint to README.md, fixes #1633 by @sftse in https://github.com/huggingface/tokenizers/pull/1709 * Upgrade to PyO3 0.23 by @Narsil in https://github.com/huggingface/tokenizers/pull/1708 * Fixing the README. by @Narsil in https://github.com/huggingface/tokenizers/pull/1714 * Fix typo in Split docstrings by @Dylan-Harden3 in https://github.com/hug | Low | 3/12/2025 |
| v0.21.0 | ## Release ~v0.20.4~ v0.21.0 * More cache options. by @Narsil in https://github.com/huggingface/tokenizers/pull/1675 * Disable caching for long strings. by @Narsil in https://github.com/huggingface/tokenizers/pull/1676 * Testing ABI3 wheels to reduce number of wheels by @Narsil in https://github.com/huggingface/tokenizers/pull/1674 * Adding an API for decode streaming. by @Narsil in https://github.com/huggingface/tokenizers/pull/1677 * Decode stream python by @Narsil in https://github.com/ | Low | 11/15/2024 |
| v0.20.3 | ## What's Changed There was a breaking change in `0.20.3` for tuple inputs of `encode_batch`! * fix pylist by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1673 * [MINOR:TYPO] Fix docstrings by @cakiki in https://github.com/huggingface/tokenizers/pull/1653 ## New Contributors * @cakiki made their first contribution in https://github.com/huggingface/tokenizers/pull/1653 **Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.20.2...v0.20.3 | Low | 11/5/2024 |
| v0.20.2 | # Release v0.20.2 Thanks a MILE to @diliop we now have support for python 3.13! 🥳 ## What's Changed * Bump cookie and express in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1648 * Fix off-by-one error in tokenizer::normalizer::Range::len by @rlanday in https://github.com/huggingface/tokenizers/pull/1638 * Arg name correction: auth_token -> token by @rravenel in https://github.com/huggingface/tokenizers/pull/1621 * Unsound ca | Low | 11/4/2024 |
| v0.20.1 | ## What's Changed The most awaited `offset` issue with `Llama` is fixed 🥳 * Update README.md by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1608 * fix benchmark file link by @152334H in https://github.com/huggingface/tokenizers/pull/1610 * Bump actions/download-artifact from 3 to 4.1.7 in /.github/workflows by @dependabot in https://github.com/huggingface/tokenizers/pull/1626 * [`ignore_merges`] Fix offsets by @ArthurZucker in https://github.com/huggingface/tokenizer | Low | 10/10/2024 |
| v0.20.0 | # Release v0.20.0 This release is focused on **performances** and **user experience**. ## Performances: First off, we did a bit of benchmarking, and found some place for improvement for us! With a few minor changes (mostly #1587) here is what we get on `Llama3` running on a g6 instances on AWS `https://github.com/huggingface/tokenizers/blob/main/bindings/python/benches/test_tiktoken.py` :  ## P | Low | 8/8/2024 |
| v0.19.1 | ## What's Changed * add serialization for `ignore_merges` by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1504 **Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.19.0...v0.19.1 | Low | 4/17/2024 |
| v0.19.0 | ## What's Changed * chore: Remove CLI - this was originally intended for local development by @bryantbiggs in https://github.com/huggingface/tokenizers/pull/1442 * [`remove black`] And use ruff by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1436 * Bump ip from 2.0.0 to 2.0.1 in /bindings/node by @dependabot in https://github.com/huggingface/tokenizers/pull/1456 * Added ability to inspect a 'Sequence' decoder and the `AddedVocabulary`. by @eaplatanios in https://github.com | Low | 4/17/2024 |
| v0.19.0rc0 | Bumping 3 versions because of this: https://github.com/huggingface/transformers/blob/60dea593edd0b94ee15dc3917900b26e3acfbbee/setup.py#L177 ## What's Changed * chore: Remove CLI - this was originally intended for local development by @bryantbiggs in https://github.com/huggingface/tokenizers/pull/1442 * [`remove black`] And use ruff by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1436 * Bump ip from 2.0.0 to 2.0.1 in /bindings/node by @dependabot in https://github.com/hug | Low | 4/16/2024 |
| v0.15.2 | ## What's Changed Big shoutout to @rlrs for [the fast replace normalizers](https://github.com/huggingface/tokenizers/pull/1413) PR. This boosts the performances of the tokenizers: 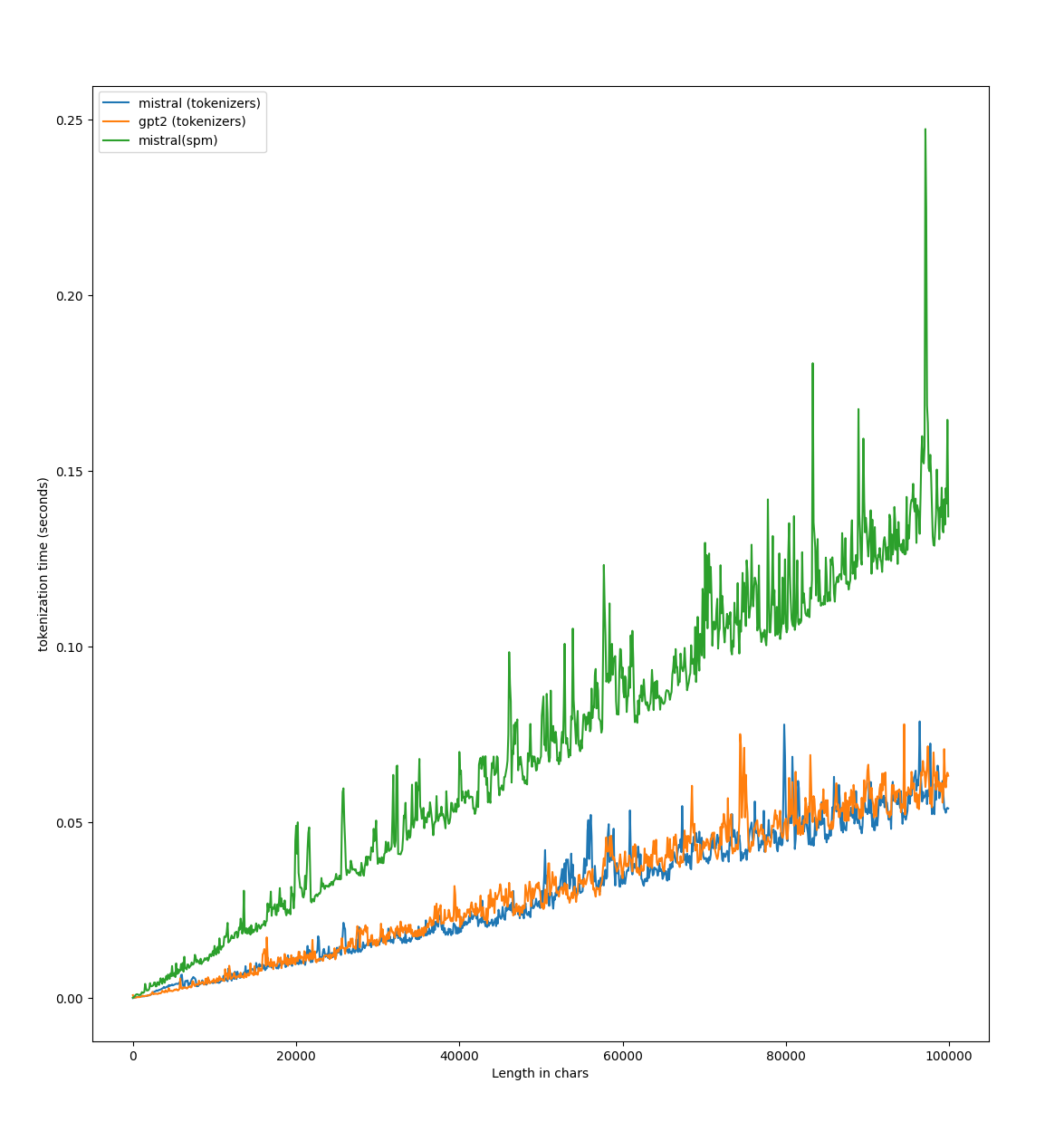 * chore: Update dependencies to latest supported versions by @bryantbiggs in https://github.com/huggingface/tokenizers/pull/1441 * Convert word counts to u64 by @stephenroller in https://github.com/huggingfac | Low | 2/12/2024 |
| v0.15.1 | ## What's Changed * udpate to version = "0.15.1-dev0" by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1390 * Derive `Clone` on `Tokenizer`, add `Encoding.into_tokens()` method by @epwalsh in https://github.com/huggingface/tokenizers/pull/1381 * Stale bot. by @Narsil in https://github.com/huggingface/tokenizers/pull/1404 * Fix doc links in readme by @Pierrci in https://github.com/huggingface/tokenizers/pull/1367 * Faster HF dataset iteration in docs by @mariosasko in https | Low | 1/22/2024 |
| v0.15.1.rc0 | ## What's Changed * pyo3: update to 0.19 by @mikelui in https://github.com/huggingface/tokenizers/pull/1322 * Add `expect()` for disabling truncation by @boyleconnor in https://github.com/huggingface/tokenizers/pull/1316 * Re-using scritpts from safetensors. by @Narsil in https://github.com/huggingface/tokenizers/pull/1328 * Reduce number of different revisions by 1 by @Narsil in https://github.com/huggingface/tokenizers/pull/1329 * Python 38 arm by @Narsil in https://github.com/huggingface | Low | 1/18/2024 |
| v0.15.0 | ## What's Changed * fix a clerical error in the comment by @tiandiweizun in https://github.com/huggingface/tokenizers/pull/1356 * fix: remove useless token by @rtrompier in https://github.com/huggingface/tokenizers/pull/1371 * Bump @babel/traverse from 7.22.11 to 7.23.2 in /bindings/node by @dependabot in https://github.com/huggingface/tokenizers/pull/1370 * Allow hf_hub 0.18 by @mariosasko in https://github.com/huggingface/tokenizers/pull/1383 * Allow `huggingface_hub<1.0` by @Wauplin in | Low | 11/14/2023 |
| v0.14.1 | ## What's Changed * Fix conda release by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1211 * Fix node release by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1212 * Printing warning to stderr. by @Narsil in https://github.com/huggingface/tokenizers/pull/1222 * Fixing padding_left sequence_ids. by @Narsil in https://github.com/huggingface/tokenizers/pull/1233 * Use LTO for release and benchmark builds by @csko in https://github.com/huggingface/tokenizers | Low | 10/6/2023 |
| v0.14.1rc1 | ## What's Changed * pyo3: update to 0.19 by @mikelui in https://github.com/huggingface/tokenizers/pull/1322 * Add `expect()` for disabling truncation by @boyleconnor in https://github.com/huggingface/tokenizers/pull/1316 * Re-using scritpts from safetensors. by @Narsil in https://github.com/huggingface/tokenizers/pull/1328 * Reduce number of different revisions by 1 by @Narsil in https://github.com/huggingface/tokenizers/pull/1329 * Python 38 arm by @Narsil in https://github.com/huggingface | Low | 10/5/2023 |
| v0.14.0 | ⚠️ Reworks the release pipeline. Other breaking changes ⚠️ : - #1335, AddedToken is reworked, `is_special_token` rename to `special` for consistency - feature http is now `OFF` by default, and depends on hf-hub instead of cached_path (updated cache directory, better sync implementation) - Removed SSL link on the python package, calling huggingface_hub directly instead. - New dependency : huggingface_hub (while we deprecate Tokenizer.from_pretrained(...) to Tokenizer.from_file(hugginngface_h | Low | 9/7/2023 |
| v0.14.0.rc1 | Reworks the release pipeline. Other breaking changes are mostly related to https://github.com/huggingface/tokenizers/pull/1335, where AddedToken is reworked ## What's Changed * pyo3: update to 0.19 by @mikelui in https://github.com/huggingface/tokenizers/pull/1322 * Add `expect()` for disabling truncation by @boyleconnor in https://github.com/huggingface/tokenizers/pull/1316 * Re-using scritpts from safetensors. by @Narsil in https://github.com/huggingface/tokenizers/pull/1328 * Reduce nu | Low | 9/7/2023 |
| v0.13.4.rc3 | Mostly checking the new release scripts actually work. ## What's Changed * pyo3: update to 0.19 by @mikelui in https://github.com/huggingface/tokenizers/pull/1322 * Add `expect()` for disabling truncation by @boyleconnor in https://github.com/huggingface/tokenizers/pull/1316 * Re-using scritpts from safetensors. by @Narsil in https://github.com/huggingface/tokenizers/pull/1328 ## New Contributors * @mikelui made their first contribution in https://github.com/huggingface/tokenizers/pull | Low | 8/23/2023 |
| v0.13.4.rc2 | ## What's Changed * Fix stride condition. by @Narsil in https://github.com/huggingface/tokenizers/pull/1321 **Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.13.4.rc1...v0.13.4.rc2 | Low | 8/14/2023 |
| v0.13.4.rc1 | ## What's Changed * Update all GH Actions with dependency on actions/checkout by @mfuntowicz in https://github.com/huggingface/tokenizers/pull/1256 * Parallelize unigram trainer by @mishig25 in https://github.com/huggingface/tokenizers/pull/976 * Update unigram/trainer.rs by @chris-ha458 in https://github.com/huggingface/tokenizers/pull/1257 * Fixing broken link. by @Narsil in https://github.com/huggingface/tokenizers/pull/1268 * fix documentation regarding regex by @chris-ha458 in https:/ | Low | 8/14/2023 |
| v0.13.4-rc2 | Release v0.13.4-rc2 | Low | 5/17/2023 |
| v0.13.4-rc1 | Release v0.13.4-rc1 | Low | 5/15/2023 |
| node-v0.13.3 | ## What's Changed * Update pr docs actions by @mishig25 in https://github.com/huggingface/tokenizers/pull/1101 * Adding rust audit. by @Narsil in https://github.com/huggingface/tokenizers/pull/1099 * Revert "Update pr docs actions" by @mishig25 in https://github.com/huggingface/tokenizers/pull/1107 * Bump loader-utils from 1.4.0 to 1.4.2 in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1108 * Include license file in Rust crate by @an | Low | 4/5/2023 |
| v0.13.3 | ## What's Changed * Update pr docs actions by @mishig25 in https://github.com/huggingface/tokenizers/pull/1101 * Adding rust audit. by @Narsil in https://github.com/huggingface/tokenizers/pull/1099 * Revert "Update pr docs actions" by @mishig25 in https://github.com/huggingface/tokenizers/pull/1107 * Bump loader-utils from 1.4.0 to 1.4.2 in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1108 * Include license file in Rust crate by @an | Low | 4/5/2023 |
| python-v0.13.3 | ## What's Changed * Update pr docs actions by @mishig25 in https://github.com/huggingface/tokenizers/pull/1101 * Adding rust audit. by @Narsil in https://github.com/huggingface/tokenizers/pull/1099 * Revert "Update pr docs actions" by @mishig25 in https://github.com/huggingface/tokenizers/pull/1107 * Bump loader-utils from 1.4.0 to 1.4.2 in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1108 * Include license file in Rust crate by @an | Low | 4/5/2023 |
| python-v0.13.3rc1 | ## What's Changed * Update pr docs actions by @mishig25 in https://github.com/huggingface/tokenizers/pull/1101 * Adding rust audit. by @Narsil in https://github.com/huggingface/tokenizers/pull/1099 * Revert "Update pr docs actions" by @mishig25 in https://github.com/huggingface/tokenizers/pull/1107 * Bump loader-utils from 1.4.0 to 1.4.2 in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1108 * Include license file in Rust crate by @an | Low | 4/4/2023 |
| node-v0.13.2 | Python 3.11 support (Python only modification) | Low | 11/7/2022 |
| v0.13.2 | Python 3.11 support (Python only modification) | Low | 11/7/2022 |
| python-v0.13.2 | ## [0.13.2] - [#1096] Python 3.11 support | Low | 11/7/2022 |
| node-v0.13.1 | ## [0.13.1] - [#1072] Fixing Roberta type ids. | Low | 10/6/2022 |
| v0.13.1 | ## [0.13.1] - [#1072] Fixing Roberta type ids. | Low | 10/6/2022 |
| python-v0.13.1 | ## [0.13.1] - [#1072] Fixing Roberta type ids. | Low | 10/6/2022 |
| python-v0.13.0 | ## [0.13.0] - [#956] PyO3 version upgrade - [#1055] M1 automated builds - [#1008] `Decoder` is now a composable trait, but without being backward incompatible - [#1047, #1051, #1052] `Processor` is now a composable trait, but without being backward incompatible Both trait changes warrant a "major" number since, despite best efforts to not break backward compatibility, the code is different enough that we cannot be exactly sure. | Low | 9/21/2022 |
| node-v0.13.0 | ## [0.13.0] - [#1008] `Decoder` is now a composable trait, but without being backward incompatible - [#1047, #1051, #1052] `Processor` is now a composable trait, but without being backward incompatible | Low | 9/19/2022 |
| v0.13.0 | ## [0.13.0] - [#1009] `unstable_wasm` feature to support building on Wasm (it's unstable !) - [#1008] `Decoder` is now a composable trait, but without being backward incompatible - [#1047, #1051, #1052] `Processor` is now a composable trait, but without being backward incompatible Both trait changes warrant a "major" number since, despite best efforts to not break backward compatibility, the code is different enough that we cannot be exactly sure. | Low | 9/19/2022 |
| python-v0.12.1 | ## [0.12.1] - [#938] **Reverted breaking change**. https://github.com/huggingface/transformers/issues/16520 | Low | 4/13/2022 |
| node-v0.12.0 | ## [0.12.0] The breaking change was causing more issues upstream in `transformers` than anticipated: https://github.com/huggingface/transformers/pull/16537#issuecomment-1085682657 The decision was to rollback on that breaking change, and figure out a different way later to do this modification Bump minor version because of a breaking change. Using `0.12` to match other bindings. - [#938] **Breaking change**. Decoder trait is modified to be composable. This is only breaking if you | Low | 3/31/2022 |
| python-v0.12.0 | ## [0.12.0] The breaking change was causing more issues upstream in `transformers` than anticipated: https://github.com/huggingface/transformers/pull/16537#issuecomment-1085682657 The decision was to rollback on that breaking change, and figure out a different way later to do this modification Bump minor version because of a breaking change. - [#938] **Breaking change**. Decoder trait is modified to be composable. This is only breaking if you are using decoders on their own. tokeniz | Low | 3/31/2022 |
| v0.12.0 | ## [0.12.0] Bump minor version because of a breaking change. The breaking change was causing more issues upstream in `transformers` than anticipated: https://github.com/huggingface/transformers/pull/16537#issuecomment-1085682657 The decision was to rollback on that breaking change, and figure out a different way later to do this modification - [#938] **Breaking change**. Decoder trait is modified to be composable. This is only breaking if you are using decoders on their own. tokeniz | Low | 3/31/2022 |
| v0.11.2 | - [#919] Fixing single_word AddedToken. (regression from 0.11.2) - [#916] Deserializing faster `added_tokens` by loading them in batch. | Low | 2/28/2022 |
| node-v0.8.3 | Release node-v0.8.3 | Low | 2/28/2022 |
| python-v0.11.6 | - [#919] Fixing single_word AddedToken. (regression from 0.11.2) - [#916] Deserializing faster `added_tokens` by loading them in batch. | Low | 2/28/2022 |
| python-v0.11.5 | [#895] Add wheel support for Python 3.10 | Low | 2/16/2022 |